
Genel olarak araştırmalarda, büyük veri gruplarının içinden daha küçük veri grupları seçilerek büyük veri gruplarının hakkında bilgi edinmek amaçlanır.
Verilerin Tanımlanması (Tanımlayıcı İstatistikler / Descriptive statistics)
Giriş :
Genel olarak araştırmalarda, büyük veri gruplarının içinden daha küçük veri grupları seçilerek büyük veri gruplarının hakkında bilgi edinmek amaçlanır. Anket çalışmaları bu yapıya bir örnektir.
Örneğin;
Pazar araştırmaları,
Kamuoyu yoklamaları,
TÜİK’in yaptığı hane halkı araştırmaları,
WHO araştırmaları.
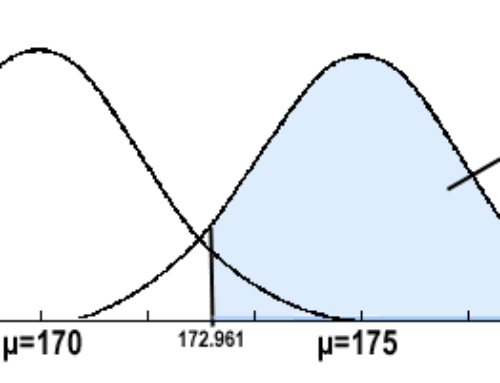
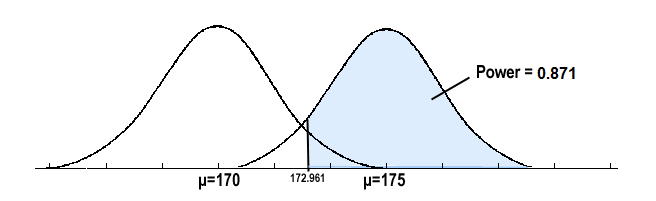
Bu tip veriler nasıl düzenlenmelidir ? Başka bir değişle bu veri toplulukları karmaşasının düzene sokulması süreci nasıl başlar? İşte tam bu noktada istatistikte sıkça karşılaşılan verilerin değerlendirme sürecinde önemli bir nokta olan değişkenlerin tek tek incelenerek tanımlanması ve özetlenmesi konusudur. Bu süreçte tanımlayıcı istatistiklerden yararlanılır. Tanımlayıcı istatistikler genel olarak Değişkelere ilişkin sıklık dağılımlarının elde edilmesi (özet tablolar) Değişkenlere ait grafiklerin çizilmesi Değişkenlere ait tanımlayıcı ölçülerin elde edilmesi İstatistiksel açıdan incelenen her değişkenin bir dağılımı mevcuttur. Bir değişkenin sıklık dağılımları gibi ölçülerinin özetlenmesi işlemine dağılım olarak nitelendirilir. Değişkenleri tek bir değerle tanımlamakla/özetlemekle kullanılan tanımlayıcı ölçüler (istatistikler) dir. Sıklık Dağılımlarının Elde Edilmesi Veri setlerinden değişkenler için tek tek özet tablolar (frekans/sıklık tabloları) oluşturarak değişkenlerin yapısı ( hangi sınıflarda yığılma var , hangi kategorik düzeyler karşılık gelen ölçüm düzeyleri farklı) hakkında bilgiler edinilebilir. Bu çerçevede sayısal verilerin genelde sınıflandırılması/gruplandırılması gerekebilir. Bir araştırmacı kanser hastalığının yaş grupları arasında değişip/ değişmediğini tespit etmek isterse yaş gruplarını sınıflamak zorunda kalacaktır. Mesala 0-5,6-11, 12-17, 18-23, … gibi burada amaç farklı yaş gruplarında kansere yakalanma riskinin aynı olup olmadığını tespit etmektir. Başka bir örnek verecek olursak farklı BKI değerlerine sahip insanların yaşam konforlarının birbirinden farklı olup/olmadığını merak eden bir araştırmacı BKI düzeylerinin çıplak değerlerini sınıflayıp bu değerlere karşılık gelen konfor ölçüm değerleri arasında bir farklığın söz konusu mudur? inceleyebilir. Yukarıdaki örnek tablomuzda sınıflanmış bir veride karşılık gelen frekans değerleri şekilde görüldüğü gibi f sütünün da bildirilmiştir. Buradan da anlaşılabileceği gibi X sütununda verinin sınıf orta noktaları belirtilmiş ve bu sınıf orta noktası bilgisi ve f frekansı değeriyle birlikte aritmetik ortalama medyan ve tepe değeri gibi istatistikleri hesaplama fırsatı bulabiliriz. Yüzdelik Frekans Dağılımı Yüzdelik frekans dağılım tablosu, her grupta, toplam veri sayısının yüzde kaçının bulunduğunu gösterir. Mutlak sayılardan ziyade, yüzdelik rakamlar daha kolay idrak edilebilir. Ayrıca, iki veya daha fazla veri kümesini karşılaştırma işlemi de yüzdelik dağılımlarla daha kolay gerçekleştirilebilir. Yüzdelik frekans değerlerini hesaplamak için, her grubun frekansını toplam frekansa oranlamamız gerekmektedir. Kümülatif Frekans Dağılımı Frekans dağılımlarını göstermek için bir başka kullanışlı yöntem de kümülatif frekans dağılımıdır. Bu dağılım, frekans dağılımından elde edilir ve her bir grubun kümülatif frekansı, ondan önceki grupların frekanslarını da içermektedir. “Kümülatif frekans hesaplanmasını ve bunun sonucunda ortaya çıkan kümülatif frekans dağılımını göstermektedir Verileri Tablolarla Özetleme Sayısal Veri Düzenlemesi Kullanacağımız tablo ve grafikler, elimizdeki verilerin özelliklerine bağlı olarak değişir.
{kind=link}